Introduction
In this article we will explain the minimax algorithm. We’ll cover game trees, the minimax algorithm itself and a simple implementation in Python. We’ll also review some popular extensions that speed up or improve upon the actions taken by minimax.
Game trees
For games with perfect information, we can model the entire play-space using a directed graph called game tree. A game tree simply illustrates all possible ways in which a game may play out. Each node described a particular state in the game, and it has one child node for each possible action that might occur from that state. To generate a game tree, we need only the rules of the game as inputs.
Let’s use the game of tic-tac-toe as an example. We have two players O and X. For the sake of explanation let us say that player O goes first. The initial state of the game then looks like this.
The children of each node represent all the possible actions that could be taken from that state. So for this node, all the possible actions correspond to Player O placing an O in one of the nine squares. We draw these states one level below the root node of the game tree and draw arrows representing a state transition between them.
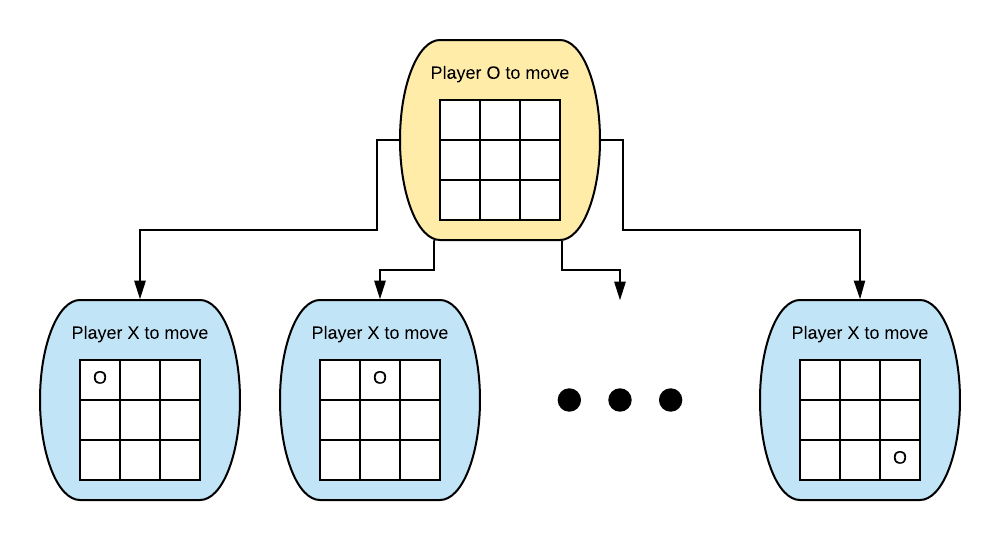
This repeats all the way down the tree until we reach a leaf node, that is a state where the game has ended. Later, we will give these leaf nodes values that represent the outcome of the game. Notice that for games in which the player making a decision alternates each turn (like tic-tac-toe) the game tree follows an alternating pattern also. That is to say that the depth of a node in the game tree determines which player makes the action in that state. Here we see for even depths Player O makes the action and for odd depths Player X makes the action.
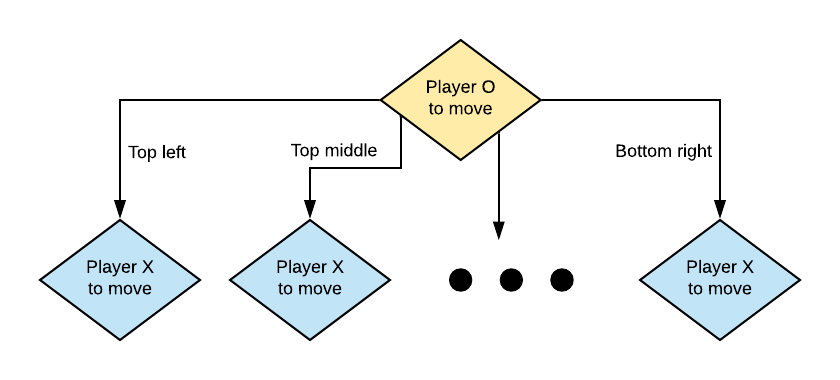
The above visualisation looks a little cluttered since we explicitly show the state of the board. Often we will instead just write the action along the transition arrow between states.
Mini-max
We have looked at how to represent games using game trees, but how should we choose the actions that we take in each state? A simple approach would be to search through the tree using a traditional search algorithm (like depth-first search or breadth-first search) to look for a node with the maximum reward for the player (or hero). However, these simple approaches fail to account for modelling the actions of the opponent (or villian).
We should expect our opponent to play rationally as we do, but how can we define a rational action? Well we know by intuition that players are trying to maximise their outcome. If we restrict the games of interest to those that are adverserial (i.e. for which the outcome for one player is the negation of the other) then our opponent (trying to maximise their own reward) inadvertently seeks to minimise our own reward. This allows us to actual construct paths to root states in the game tree.
For example, take the above example. We can draw this as a game tree.
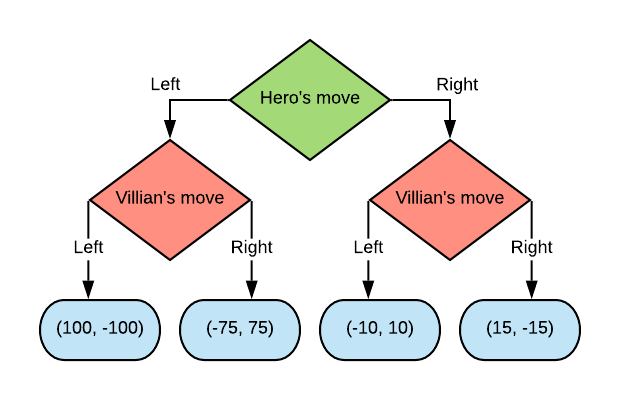
Since we know exactly how the game will play out from each of the Villian nodes, we can just assign an outcome to them.
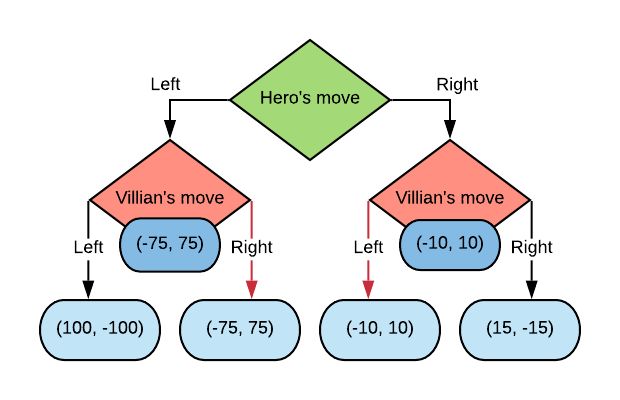
Now since the Hero is a maximiser of their own reward, the choice here is clear and the Hero should choose to play the action “Right” which leads to an outcome of (-10, 10).
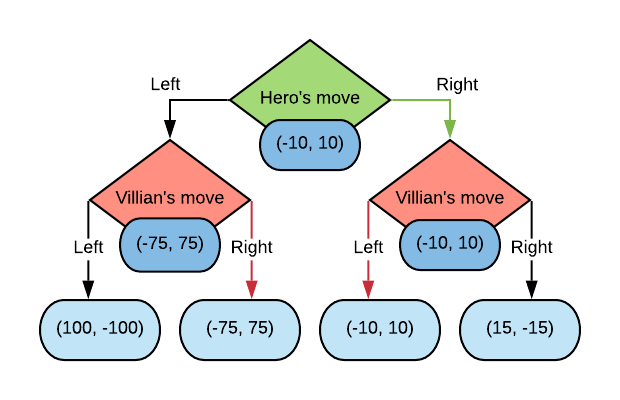
We can generalise this process as an alternation between maximising (turns that the Hero plays) and minimising (turns that the Villian plays). Under the assumption that the outcomes for the Hero and Villian are negated, we can simplify the tree to just show the Hero’s outcome at the root.
Here’s the above game with the simplified tree.
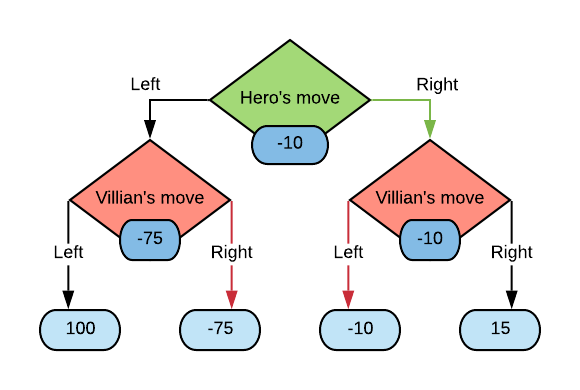
We call the computed outcome values (shown in blue) at each node the minimax values.
Pseudocode
We can compute minimax values simply by making a post-order traversal through the tree. At a particular node, we compute the minimax values for each of the children, then take either the max or the min depending on whether we are at a maximising depth or minimising depth.
class RootNode:
def __init__(self):
self.value = 0
def get_minimax_value(self, maximising = True):
return self.value
class ChoiceNode:
def __init__(self):
self.children = []
def get_minimax_value(self, maximising = True):
child_values = [child.get_minimax_value(maximising = not maximising)
for child in self.children]
if maximising:
return max(child_values)
else:
return min(child_values)
Tic Tac Toe in Python
We will implement a small tic-tac-toe node that records the current state in the game (i.e. the board position and the player that is next to move).
from copy import deepcopy
class TicTacToeNode:
def __init__(self, board = None, player = "O"):
if board is None:
board = [[" " for _ in range(3)] for _ in range(3)]
self.board = board
self.player = player
def children(self):
if self.winner() is not None:
return
for row_num in range(3):
for col_num in range(3):
if self.board[row_num][col_num] == " ":
next_board = deepcopy(self.board)
next_board[row_num][col_num] = self.player
next_player = "O" if self.player == "X" else "X"
yield TicTacToeNode(board = next_board, player = next_player)
def winner(self):
# Check for horizontal winners
for row_num in range(3):
if self.board[row_num][0] == self.board[row_num][1] == self.board[row_num][2] != " ":
return self.board[row_num][0]
# Check for vertical winners
for col_num in range(3):
if self.board[0][col_num] == self.board[1][col_num] == self.board[2][col_num] != " ":
return self.board[0][col_num]
# Check for diagonal winners
if self.board[0][0] == self.board[1][1] == self.board[2][2] != " ":
return self.board[1][1]
if self.board[2][0] == self.board[1][1] == self.board[0][2] != " ":
return self.board[1][1]
# Check for draw
if " " not in "".join(["".join(row) for row in self.board]):
return 'D'
return None
def __str__(self):
row_strings = [" | ".join(row) for row in self.board]
return ("\n" + '-'*9 + "\n").join(row_strings)
Here we also implement a method winner which returns the character of the winning player (or D for a draw) if the game is over. We can apply minimax and search through the child states of the initial game state (i.e. an empty board with player O to move) and evaluate the minimax value.
n = TicTacToeNode()
def minimax_value(node):
if node.winner() is not None:
return 1 if node.winner() == 'O' else 0 if node.winner() == 'D' else -1
child_values = [minimax_value(child) for child in node.children()]
assert(len(child_values) > 0)
if node.player == 'O':
return max(child_values)
else:
return min(child_values)
print(f'Minimax value for empty board is: {minimax_value(n)}')
print(n)
# Minimax value for empty board is: 0
# | |
# ---------
# | |
# ---------
# | |
Here we can see that for an empty board, optimal play from both sides will lead us to a draw! How about if we play out some moves?
n = next(next(TicTacToeNode().children()).children())
print(f'Minimax value for non-empty board is: {minimax_value(n)}')
print(n)
# Minimax value for non-empty board is: 1
# O | X |
# ---------
# | |
# ---------
# | |
Now we see that from this state if we play optimally we will always be able to win! Note that in the previous case with the empty board, a minimax value of 0 does not mean that we cannot win, but that we can guarantee a score of at least 0. If the opponent plays sub-optimally (like in the moves shown above) then we may reach a state from which we can always win.
Extensions to mini-max
The most popular extension of mini-max is a method of computing the minimax values faster called alpha-beta pruning. This method takes advantage of the fact that there is no need to traverse some subtrees in the game tree where a better option for a player already exists. For example
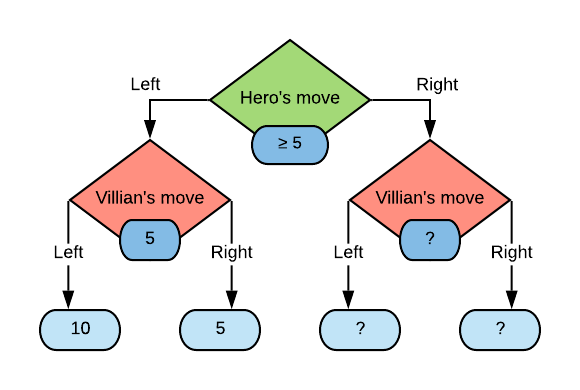
Here we have fully traversed the subtree for when the hero plays “Left” and arrived at a minimax value of 5. This means that the hero can score at least a 5 when playing this game, and hopes to find a better option when traversing the subtree for the “Right” action.
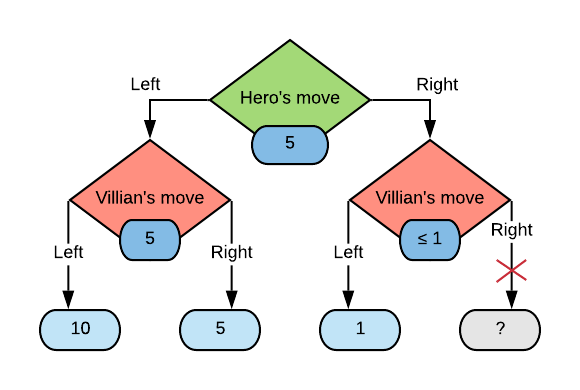
After looking at the path of the hero playing “Right” and the villian playing “Left” we find that the outcome was 1. Now we can see that the villian can score 1 and since it acts as a minimiser, the minimax value for that state will be less than or equal to 1. Therefore it is always less than the 5 in the other villian node reached when the hero plays “Left”. Therefore we do not need to traverse the subtree for when both players play “Right” since we know the hero will never play “Right”.
More detail on alpha-beta pruning can be found in the CS188 slides.
Recall that so far we have restricted our discussion of minimax to games in which the hero and villian are in direct opposition (i.e. the reward for one is the loss for the other). Suppose instead instead that this is not the case, and the opponent’s reward may be completely unrelated to the hero’s reward. Instead we model the decision of the villian as a discrete probability distribution over the actions avaliable to them in a particular state. Note that for the adverserial games discussed above the discrete probability distribution places all the probability mass on a single option (since we model the villian as playing optimally). In this generalisation called expectimax we choose the option that maximises the expected reward for the hero, rather than the worst reward.
Concretely suppose that the hero has a set of actions available to them \(\mathcal{A}_H = \{a_h^1, \ldots, a_h^k\}\). For each action \(a_h^i\) the hero makes, the villians response is modelled by the random variable \(\mathcal{A}_V^i = \{a_V^{i,1}, \ldots, a_V^{i,n}\}\) and let \(V\) be a function that gives the value of the villians response.
\[ \pi(S) = \underset{a_h^i \in \mathcal{A}_H}{\text{arg max}} \,\, \mathbb{E}[V(\mathcal{A}_V^i)] \]
With an example, suppose we have the following game tree.
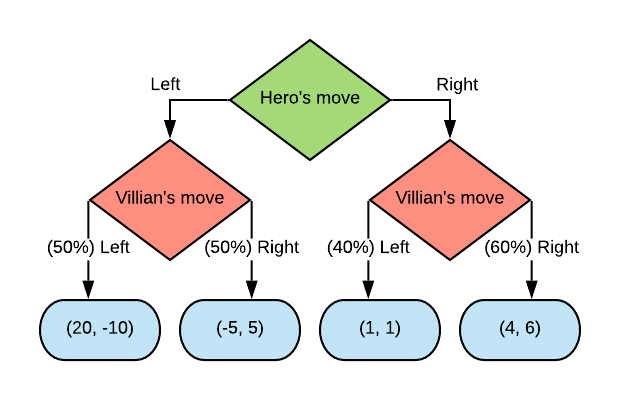
The minimax solution to this game is for the hero to play “Right” with the goal of preventing themselves from scoring the -5, however when we look at the expectations of each move, on average playing “Right” yields 2.5 (\(1*0.4 + 4*0.6 = 2.8\)) buy playing “Left” yields 7.5 (\(20*0.5 + (-5)*0.5 = 7.5\)). Therefore the expectimax solution is to play “Left” in this game. The drawback with this approach is that we require a model of the exact probability distribution of the villians moves in each state.
References
Abbeel, P., Klein, D. (2018). CS 188 - Introduction to Artificial Intelligence. Retreived from https://inst.eecs.berkeley.edu/~cs188/fa18/